Code Motion 2019 Berlin – conference report


I attended the first day of the Code Motion 2019 conference in Berlin. In this blog post, I like to share the things I learned. There are also two more particular topics I put in individual posts:
- The role of an Engineering Manager
This article sums up the general learnings which would not conduct a whole article.
Cultivating Instinct by Katrina Owen
The opening keynote was from Katrina, who is working at Github. She talked about instinct or how people change their behavior over time as they get more advanced in their field.
The fundamental idea of this talk is that every five years, the number of developers double. That means that 50% of all developers have less than five years of experience.
Knowing this fact, it's crucial to have in mind how people with different experience levels behave. In general, novices pay more attention to every detail. Experts may not pay that much attention to every detail as they are familiar with that topic. It would help experts to have this in mind when they work with novices. Novices will discover more and more details on their way. That helps them to learn and understand. So, experts should not get frustrated if a beginner is moving in different directions. They will learn something on the way. On the other hand, experts should be aware that there are some topics where it could be helpful to pay more attention to the details. So, you don't overlook some valuable information.
Over time, when novice transforms to experts, there is a chance they develop something like an instinct. An instinct in software engineering is when you know what to do immediately. There are people when they see a piece of code, and they will find the bug within a few seconds. Having this instinct is highly helpful for a team.
Uber-Scale Monitoring for Everyone with M3 by Matt Schallert
Matt spoke about monitoring and how to scale it. Monitoring is done with metrics that are collected from/about your application and infrastructure. While the architectural paradigm of microservices is getting more and more popular, this architecture paradigm is also changing the monitoring requirements. Now we have to monitor the communication and collaboration of our services as well as the same metrics we collected before microservices came up.
The default solution for monitoring is Prometheus. That's an all-in-one solution to gather, query, and alert on metrics. The only issue you get with Prometheus is that long-term storage, as well as a scale out storage, is out of scope for the Prometheus project. As soon as you have to scale your application, you will hit a limit where it's not possible to scale up your monitoring any further.
Here comes M3 to rescue. M3 is an open-source platform build to store your metrics data on scale.
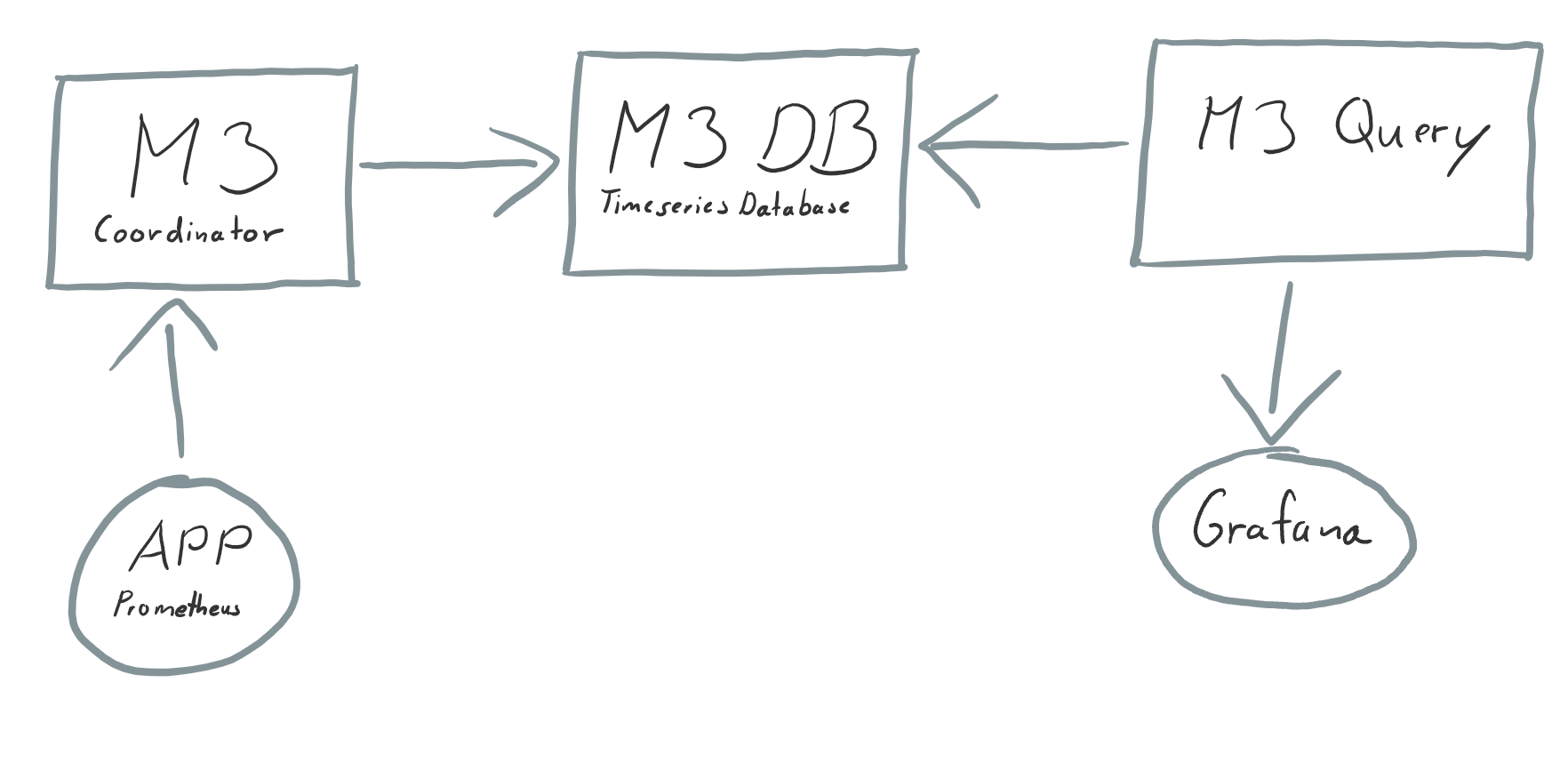
The pictures show how the M3 monitoring system works. Prometheus is pushing metrics to the M3 coordinator. The coordinator saves the metric data in the M3 database, which is a time-series database. Later on, Grafana can query these data from M3.
The scaling happens in the M3 database. M3 DB shards the data across the different nodes and replicates them. To get long time data storage M3 DB distinguishes between a short-term store for many metric data points and a long-term store for aggregated metrics. The short term data points could have a resolution of 1 second, and the long-term metrics could have a resolution of an hour, for example.
If you use Kubernetes, M3 brings a particular M3 Operator to get an integrated monitoring solution within your operating environment. M3 can also handle Prometheus data input as well as Graphite data to integrate and scale in your situation quickly. In the opinion of the speaker, you should always start with Prometheus. As soon as you need to scale, you can add M3 to your infrastructure.
Besides the technical part of M3, the speaker also talked about different levels of metrics.
Business metrics: usually, the marketing team is taking care of.
Application metrics: usually, the development team is taking care of.
Infrastructure metrics: usually, the operation or infrastructure teams are taking care of.
Metrics are used to figure out if your system is operating well. If you work in silos and every department is just looking at their metrics, it's usually much harder to solve an issue with your metrics data. You should have all the metrics in the same store, and everyone should have access to them. Only then it's possible to speed up the troubleshooting if something is broken.
Designing your Career: Explore a Career Change and Do What You Love by Dr. Aygul Zagidullina
Aygul is a Google Developer Expert and talked about her career advice for software engineers. A career doesn't mean a management career. A career within software engineering is also a good option and depending on your needs; it’s maybe the better option then the management path.
Here are her career tips:
#1) Believe in yourself and build self-confidence
#2) Be curious; never (ever) stop learning
#3) Dream big
Always have an ongoing "One Day" or "Maybe" list and review it regularly. From time to time, pick one of the items on this list, add one or more next step, and a deadline: now you have a project.
#4) Learn how to network (effectively)
#5) Get organized, focused, and priorities
Reduce the time you procrastinate. Work on the things that matter for you. Get things done.
#6) Get comfortable with selling yourself
At least during job interviews, that's important. But also, besides that, it helps in very different scenarios like during networking as well.
#7) Volunteer: give back to the community
You consume things from several communities. If it's open-source software, online articles, meetups, or a community organized conference. You should also give something back. This leads to more visibility for yourself and also drives the community forward.
#8) Be ready to work hard
This was meant in a way like: be prepared to deliver the best work you can do. She used a quote from Richard Branson, "Think, what's the most amazing way to do it." and then do it so.
#9) Embrace discomfort, be willing to fail
The more you try, the more you will fail. Failure is a normal process of learning, and you should not get pushed back by that.
Conference conclusion
Some words about the conference in general. The conference tries to gab the bridge between the human factor and the tech side quite well. I would have wished for more tech-related topics, that's why I only attended day one. For a community-organized conference, it's imposing what they delivered. The speaker lineup was great, and the diversity of different topics was very appealing. I just had the feeling that the location was a bit overcrowded. Nevertheless, I left with a few inspiring thoughts. Which is an essential thing in a conference for me.
Title photo by The Climate Reality Project on Unsplash